Portfolio
A small glance to my projects
Dynamic Rhythms
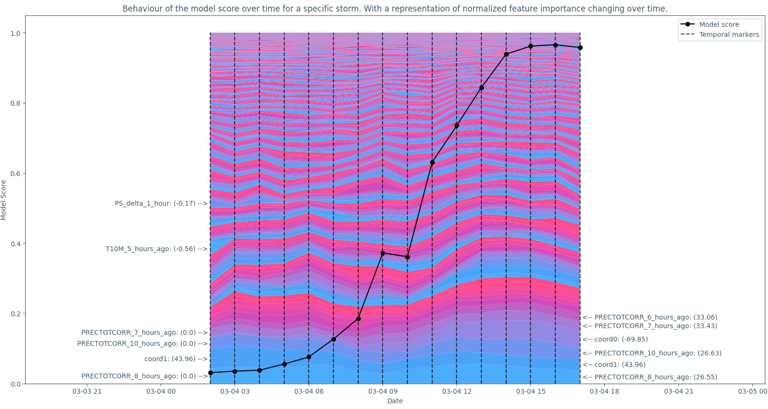
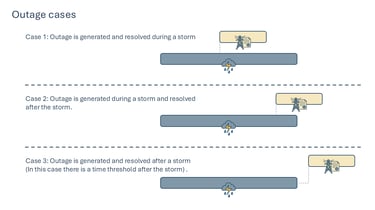
Anticipating power outages caused by extreme weather events.
What we get from the solution?
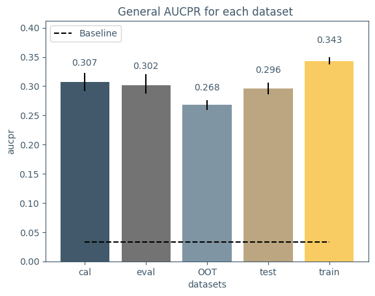
This solution enables the anticipation of high-impact situations with enough lead time to activate prevention, response, or mitigation strategies, both for infrastructure management and public safety.
Key Takeaway:
Solving complex problems doesn’t always require subject-matter expertise. Outages and storms weren’t domains I had previous experience in, but that didn’t stop me. 𝘍𝘰𝘳 𝘮𝘦, 𝘥𝘢𝘵𝘢 𝘢𝘤𝘵𝘴 𝘢𝘴 𝘢 𝘵𝘳𝘢𝘯𝘴𝘭𝘢𝘵𝘰𝘳 𝘰𝘧 𝘪𝘯𝘧𝘰𝘳𝘮𝘢𝘵𝘪𝘰𝘯: it helps reveal patterns and relationships that guide you toward meaningful solutions. With the right tools and mindset, even unfamiliar challenges can become solvable. Often, it’s not about knowing everything, it’s about knowing how to listen to what the data is trying to tell you.
What was the project about?
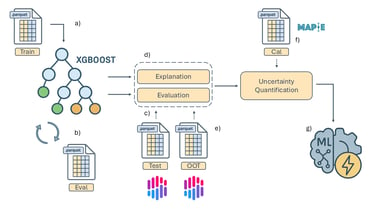
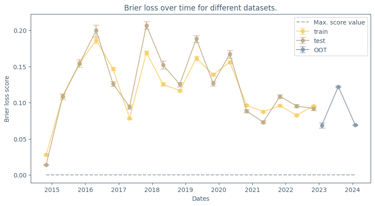
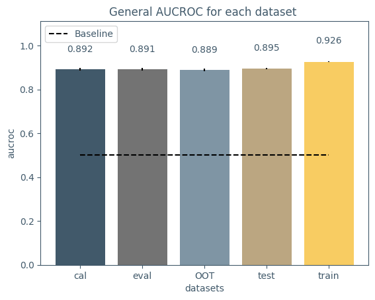
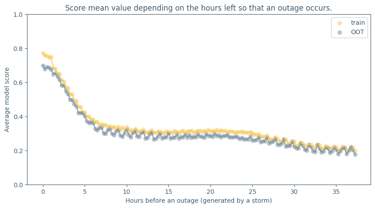
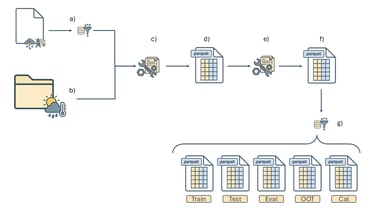
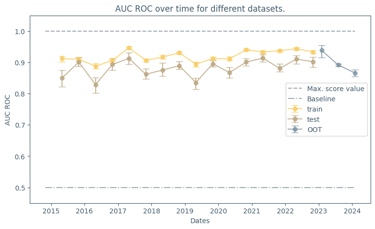
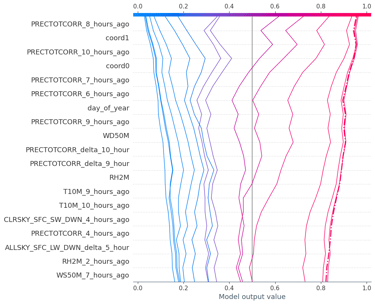
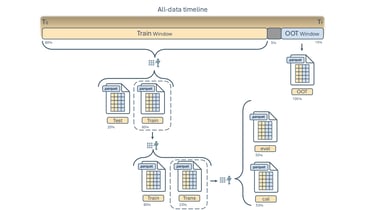
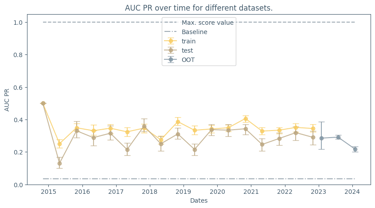
I developed a supervised machine learning model addressing the project from an end-to-end data development perspective. The resulting model achieved strong predictive performance and was also designed to work as a potential real-time forecasting mechanism. One aspect I especially appreciated was the emphasis on XAI: the contest didn’t just focus on performance, it encouraged model understanding and how it connects to real-world reasoning; which is an essential trait when building critical decision-making systems.



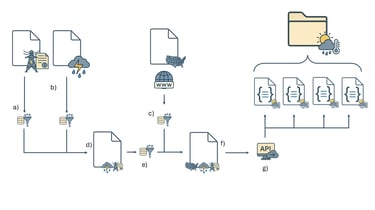
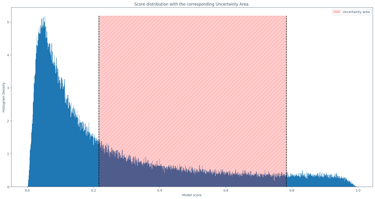
MetaKaggle Hackaton:
Echoes of Interest
This writeup uses Meta Kaggle data to show how the community adds a layer of semantic richness on top of Kaggle Datasets through interactions like voting that can help to power personalized recommenders and improve the platform. It’s a fantastic use of the Meta Kaggle dataset and presents really useful suggestions and ideas in a compelling and fun way. Overall, this project was a very strong end-to-end analysis and proof of concept.
Data and Information
Kaggle Stutcture
The first step was to locate all the relationship between the data of Kaggle
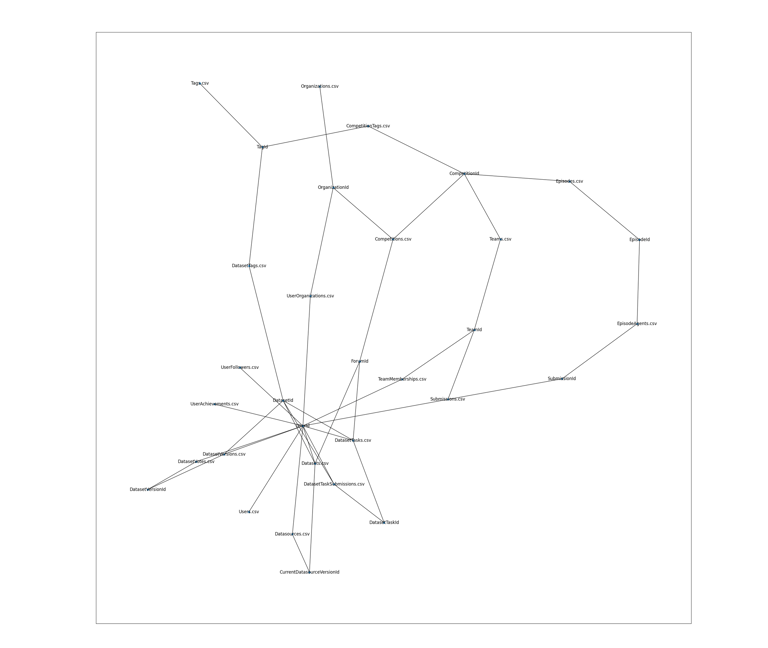
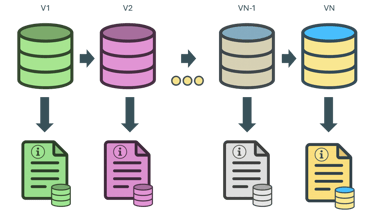
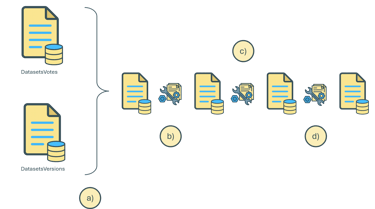
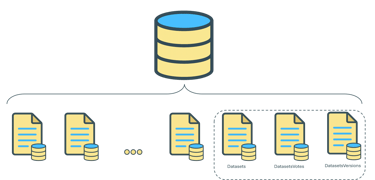

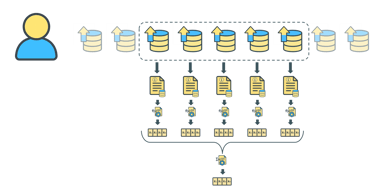

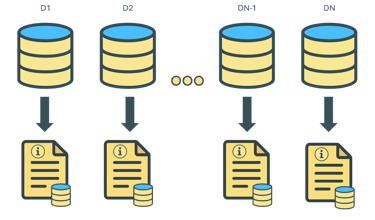
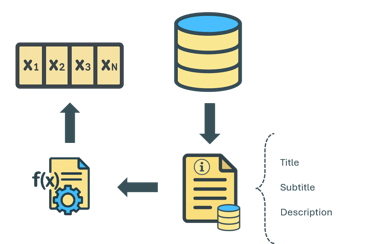
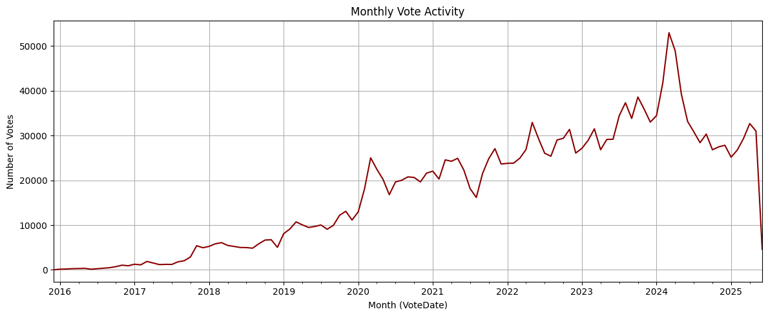
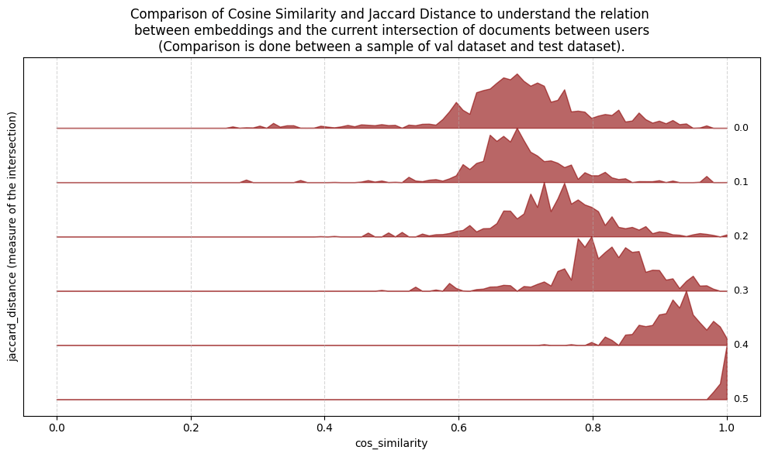
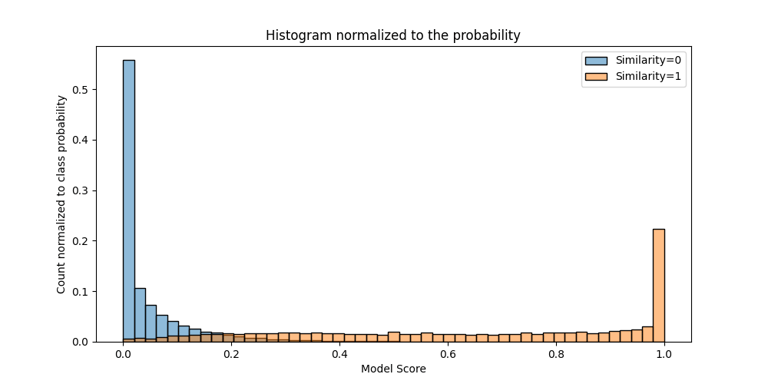
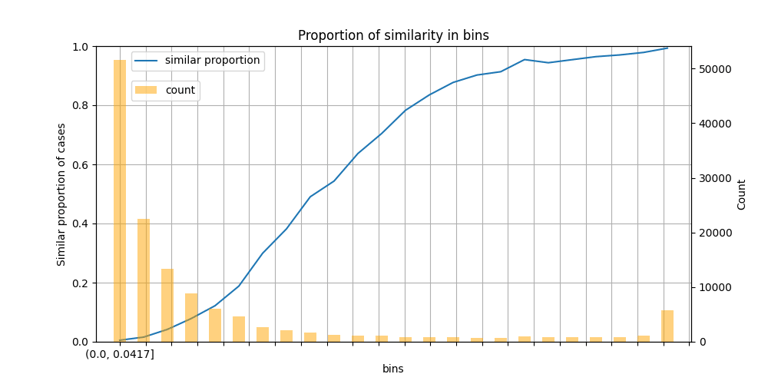
Vote activity was registered over time. Relation between the recommendation was computed to determine similarity.

Our write-up consisted of creating a recommendation system based on the interaction between user behavior (mainly votes) and the datasets available on the platform.
The system leverages the semantics of dataset descriptions, modeled using Doc2Vec, which allowed us to capture patterns of interest and generate unexpected connections between users and datasets.
The system was able to uncover relevant but underexposed datasets, highlight connections between users with aligned interests, and demonstrate that even without shared interactions, there are echoes of curiosity we can model and turn into new paths of discovery.


Predicting Complete Pass
Probabilities with Graphs
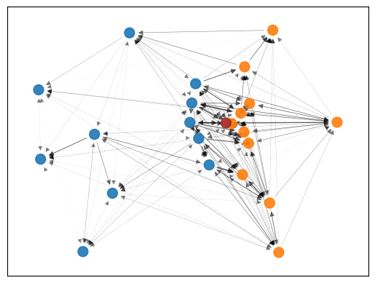
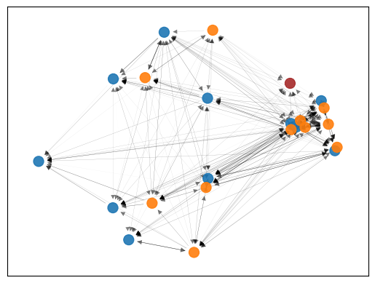
A model to predict the completion probability of a pass in American football, using graph-based representations of player interactions from NFL Big Data Bowl tracking data.
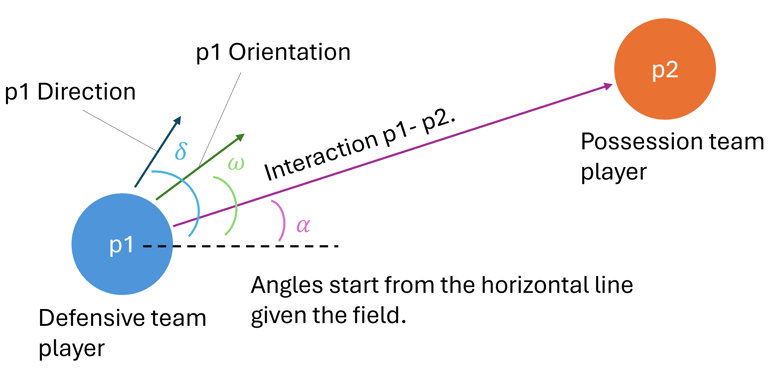
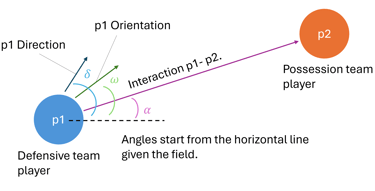
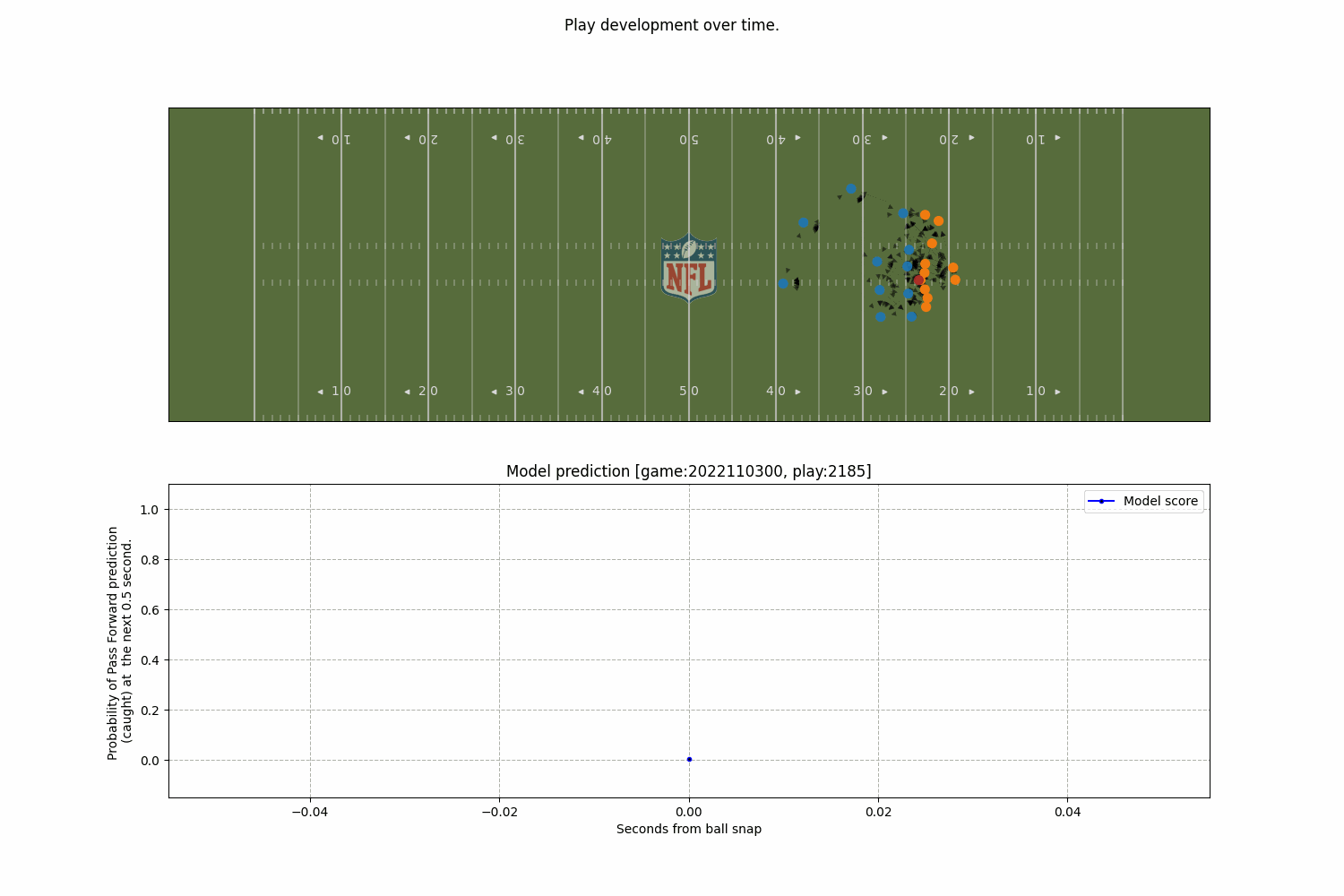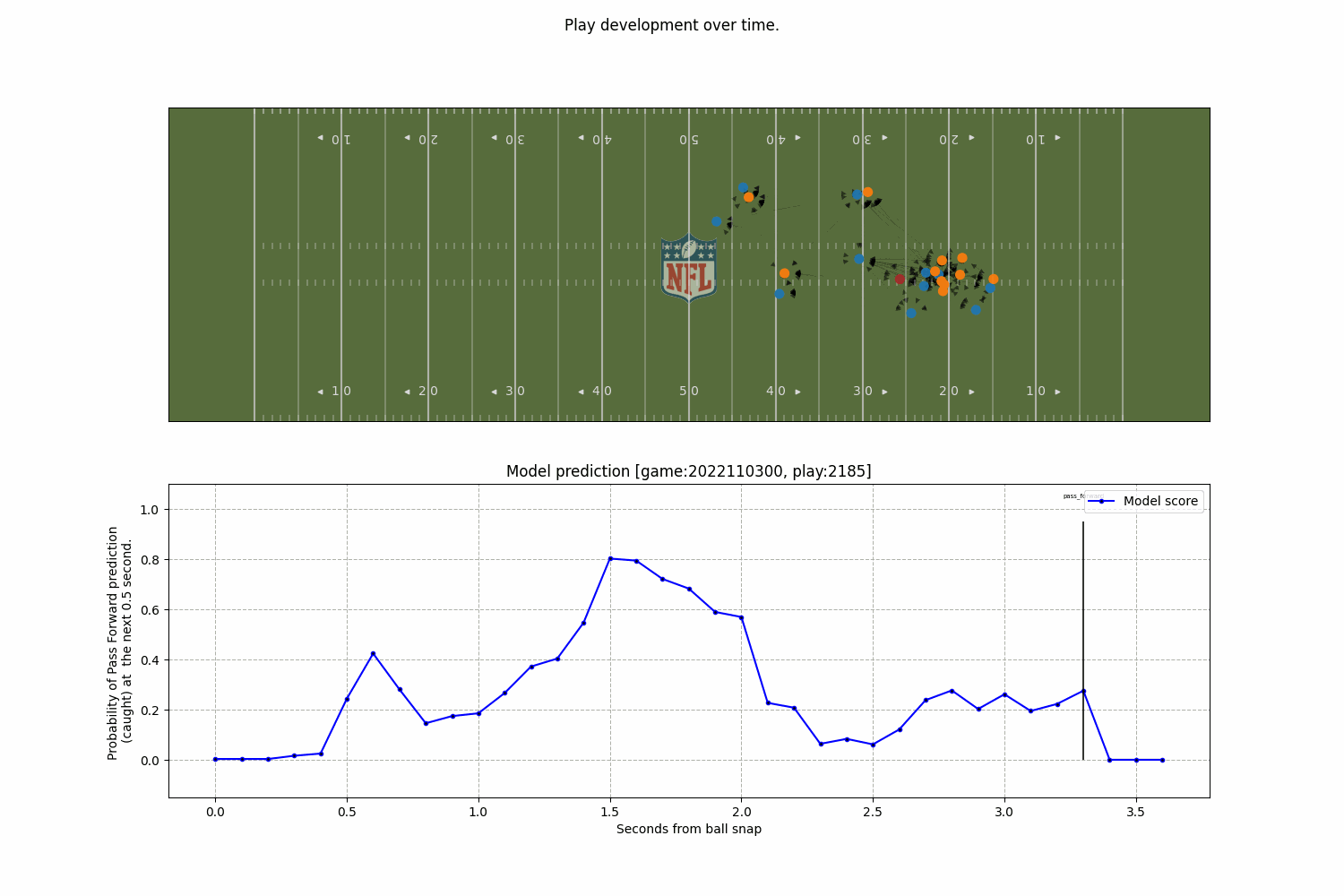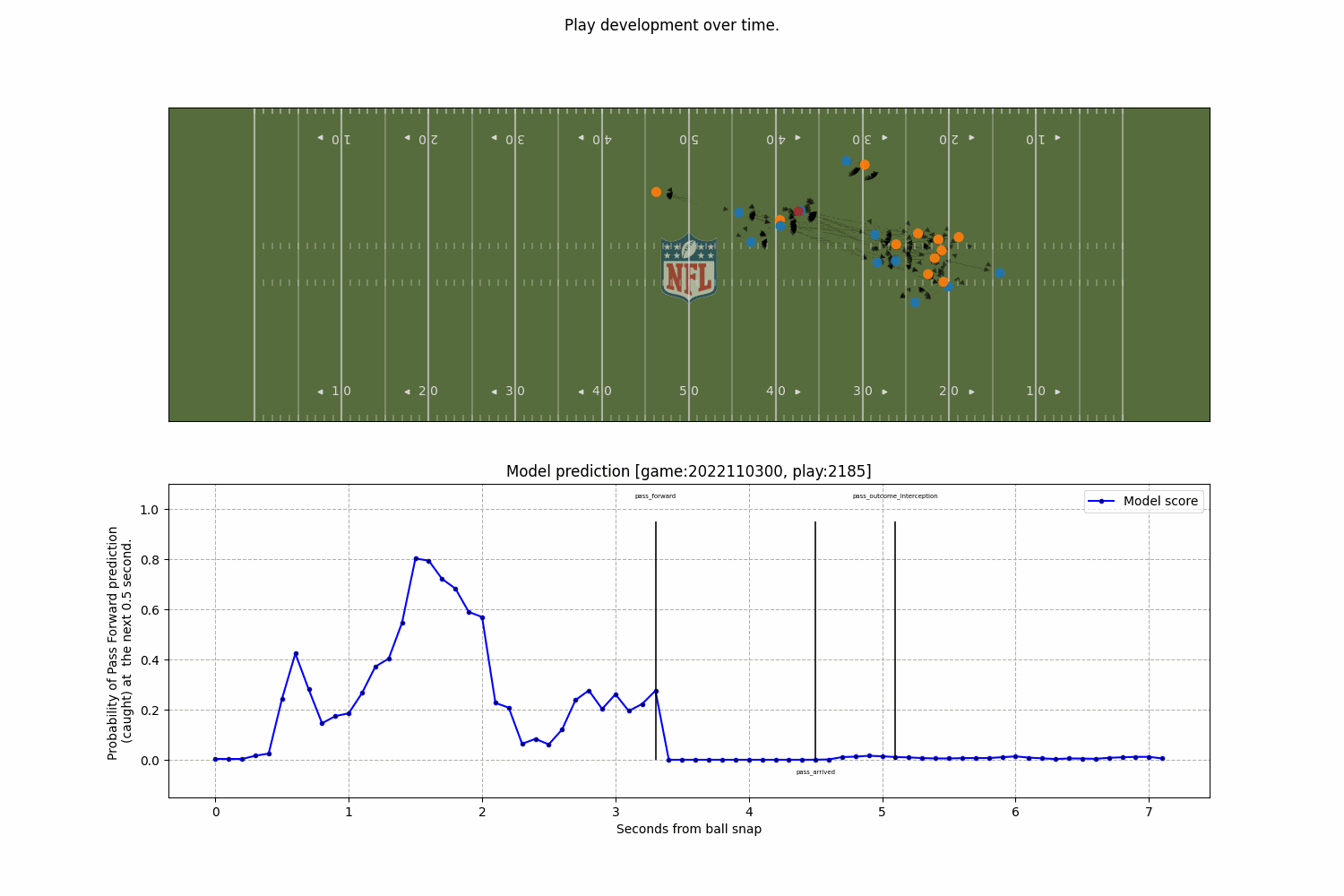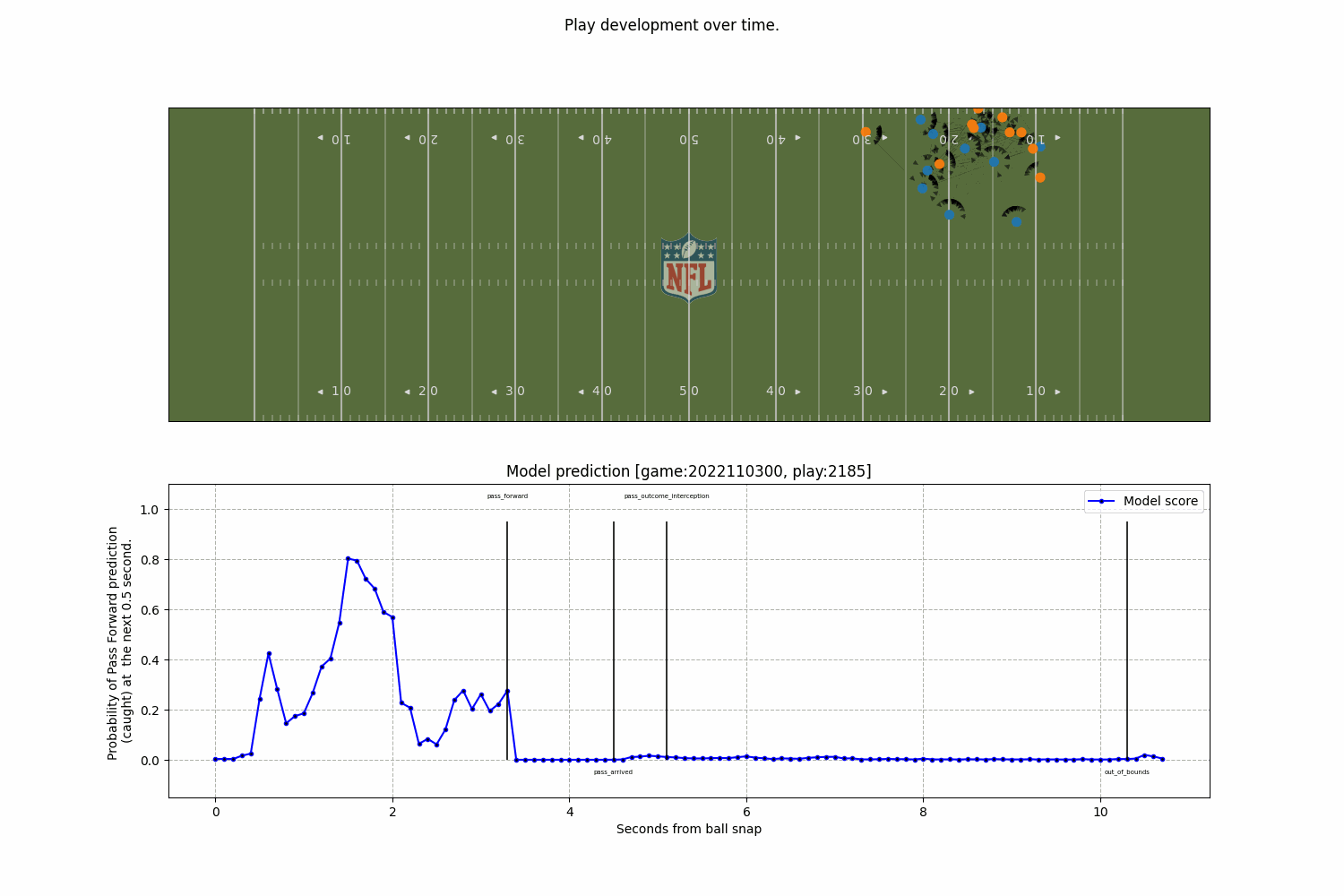
Model
This year, I had the opportunity to return to COMIA (Mexican Congress on Artificial Intelligence) [https://lnkd.in/df_yfCte], this time to present our project titled “𝙋𝙧𝙚𝙙𝙞𝙘𝙩𝙞𝙣𝙜 𝘾𝙤𝙢𝙥𝙡𝙚𝙩𝙚 𝙋𝙖𝙨𝙨 𝙋𝙧𝙤𝙗𝙖𝙗𝙞𝙡𝙞𝙩𝙞𝙚𝙨 𝙬𝙞𝙩𝙝 𝙂𝙧𝙖𝙥𝙝𝙨.”
Together with Javier de Alba Pérez, we developed a model to predict the completion probability of a pass in American football, using graph-based representations of player interactions from NFL Big Data Bowl tracking data.
Graph representation
What’s most exciting isn’t just the model’s accuracy; but how a relational representation, where players are nodes and their interactions are encoded as edges, helps capture complex in-game dynamics in a way that’s more interpretable and decision-friendly.
It’s not just about predicting a pass—it’s about grasping the essence of the game in real time.
This project reinforced something I deeply believe in: the power of combining data, technique, and context to solve problems that may seem unrelated to traditional AI, yet carry immense practical value.
At its core, it’s still what I’m most passionate about: understanding complex systems and building data-driven solutions.
COMIA
A paper was created and submitted into the COMIA conference.



Food Generation with AI.
A project that uses AI and genetic algorithms to create sustainable food substitutes with taste and nutrition comparable to traditional products.


Why it matters
Food innovation has traditionally relied on trial, error, and expert intuition. By applying AI, this project shows how technology can identify hidden patterns in flavor molecules, nutritional profiles, and ingredient properties to propose creative alternatives. Such an approach opens the door to sustainability, diversification, and accessibility in the food industry, helping to reduce waste and broaden dietary options while keeping taste and nutrition intact.
Objective
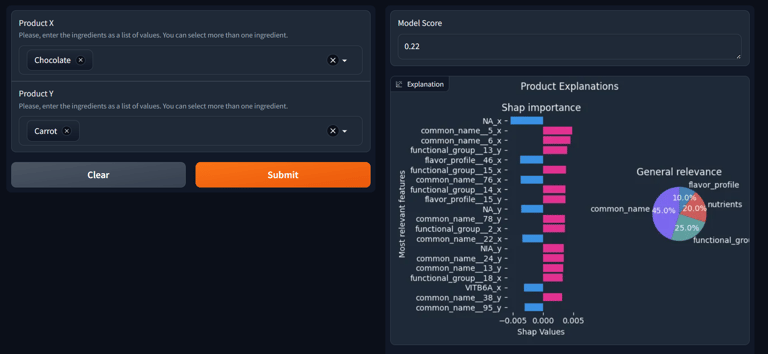
This project explores how artificial intelligence can design new functional food products by combining machine learning and genetic algorithms. The goal is to generate substitutes for everyday foods—such as cheese, milk, and butter—that preserve their nutritional and sensory qualities while using entirely different ingredients.
The project developed a Random Forest model that learned to recognize similarities between foods with high accuracy (AUC-PR: 0.898). This model was then embedded in a genetic algorithm that iteratively proposed optimized ingredient combinations. The resulting substitutes achieved 80% probability of matching flavor and nutritional properties of the original foods. By blending predictive modeling with generative algorithms, the project demonstrates how AI can be a powerful tool for designing the foods of the future.
Latin Food
The abstract of this research was presented at the Latin Food 2024 conference, by AMECA





COMIA
A paper was submitted into COMIA where a presentation was also given. The 2nd best paper was achieved at the conference.




Intel
The project was submitted into a contest from intel called "Acelerando la innovación en méxico con IA" and was selected as the top 10 applications.


Talks
Beyond its technical depth, the project has sparked widespread interest and dialogue—leading to talks at institutions such as the Universidad Católica del Uruguay (UCU), Université Laval (Canada), the Sociedad Matemática Mexicana, and LABINAR (Laboratorio de Inteligencia Artificial). These presentations have helped open multidisciplinary conversations around how AI can creatively and responsibly contribute to food innovation.








SeGuía
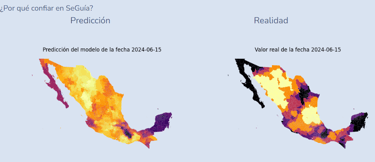
SeGuía is an artificial intelligence model that can identify droughts up to six months in advance.
What is the project about?
SeGuía is a project aimed at tackling the issue of droughts in Mexico at its root. It does so through the development of a predictive model that generates a coefficient representing the probability of a drought occurring in the following month.
The project was led by Ana Sofía López Zúñiga and myself, with the valuable support of Alan Jesús Cortés de la Torre, Maximiliano Bernal Temores, Guillermo León Silva Ocegueda, and Daniel Caldera Hernández.
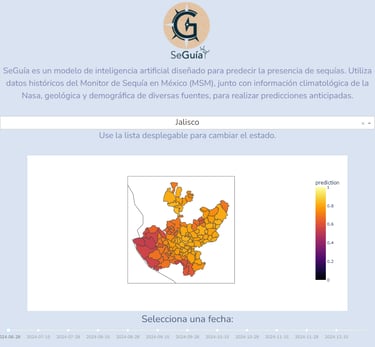

POC
The project aims to transform drought management practices, enabling preventive actions that reduce economic, social, and environmental impacts.
The project is technically viable and feasible thanks to:
Availability of open data (NASA, CONABIO, CONAGUA, Mexican demographic data).
Accessible technology, using Python and robust machine learning techniques.
Team expertise, with strong capabilities in data integration and predictive modeling.

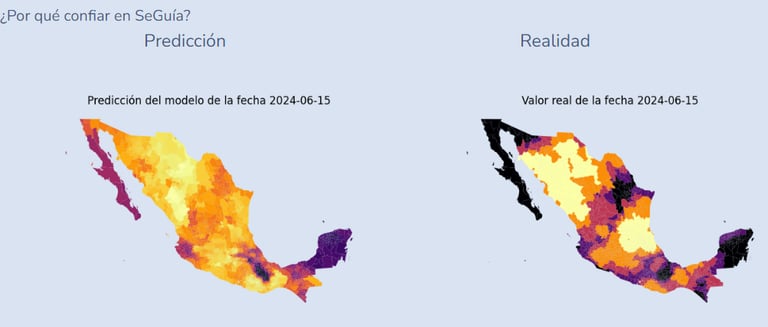
In terms of innovation, SeGuía stands out by:
- Offering early drought prediction and error quantification.
- Enabling interpretability through relational data representations.
- Being scalable both nationally and internationally, adaptable to diverse contexts.
The business model includes partnerships with governments, international organizations, and the private sector, along with revenue generation through APIs, technology licensing, and custom data analysis services.
In summary, SeGuía represents a disruptive and scalable solution with the potential to transform drought management, reduce economic, social, and environmental losses, and contribute to a more resilient future.
Reality representation
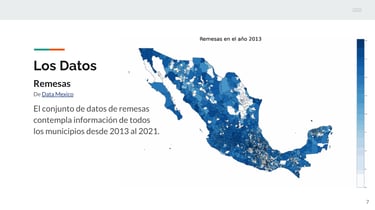
Towards Understanding Remittances and Financial Inclusion
This project was developed for the third edition of Desafío Data México, which focused on financial inclusion and MSMEs, organized by the Ministry of Economy. The team members were Raúl Sánchez, Omar Peña, and myself, and our efforts earned us third place at the national level.
The team
Objective
The goal of this project was to explore whether there is a relationship between remittances and financial inclusion. To achieve this, we applied machine learning techniques that systematically identified connections between these two concepts through statistical modeling.
Exploring the relationship between remittances and financial inclusion


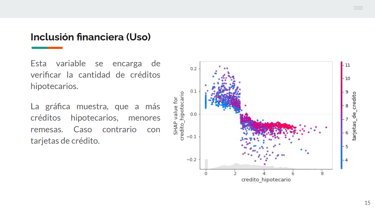
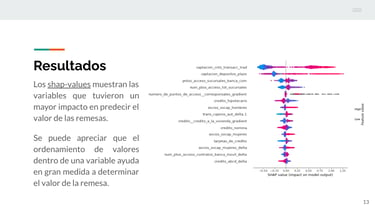
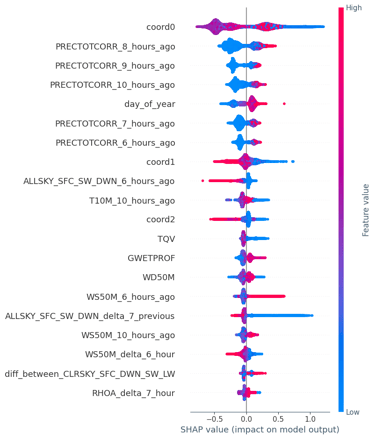
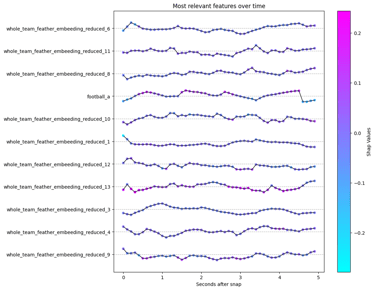
Specifically, we used the model explainability technique SHAP. To do this, we built a regression model aimed at predicting the value of remittances sent in each municipality per month, using only financial inclusion data in Mexico—that is, access to banks, credit cards, and different financial tools such as loans and mortgages.
This provided the necessary input to apply the explainability technique, allowing us to understand the reasons behind the model’s predictions.

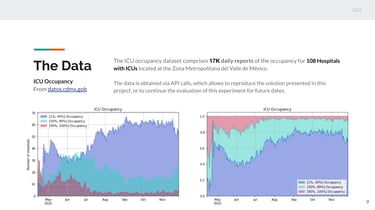
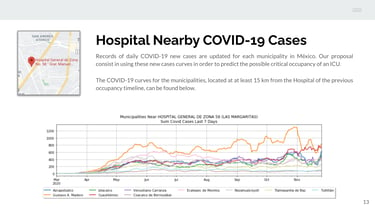
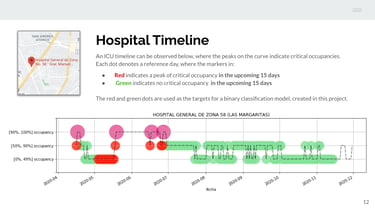
Intensive Care Unit Occupancy:
Predicting the probability of critical occupancy in an intensive care unit (ICU) given COVID data.
The team
This project was developed for a competition called Desafío Data México, in its second edition, organized by the Ministry of Economy. The participants were Raúl Sánchez, Omar, Alberto, and myself. The challenge aimed to describe what was happening in Mexico during the pandemic from different perspectives; our team decided to build a predictive model. The competition lasted about a week, which required constant and efficient development, and thanks to our efforts, we achieved second place at the national level.


The model
In this project, the goal was to design a machine learning model capable of predicting the probability of critical occupancy in an intensive care unit (ICU) within the context of the COVID-19 pandemic. The objective was to provide real-time predictions for the following 15 days.


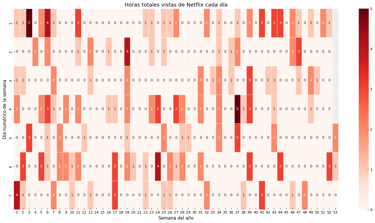
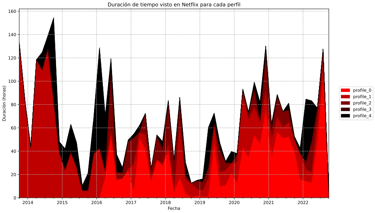
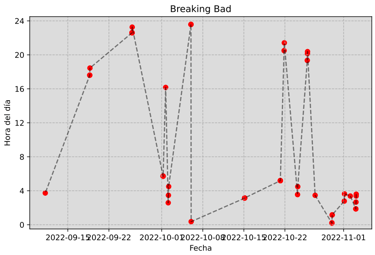
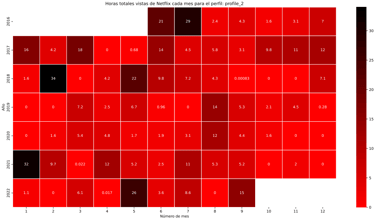
Netflix Data
A project that turns your Netflix data into clear visual insights of your viewing habits and patterns.
The model
This project is designed to give a simple but powerful look into Netflix viewing habits. By working with your own Netflix data, it generates easy-to-read reports that show how much time you’ve spent watching, when you watched, and what patterns emerge over time.
The idea behind this project is to make personal data more understandable and useful. Instead of raw files full of numbers, the project organizes everything into visual insights that are both clear and fun to explore. It’s built in a way that is easy to run, with a clean structure that keeps things organized and accessible, even for those new to data analysis.
With just a few steps, you’ll be able to see:
Viewing duration by profile – who’s watching and for how long.
Series timelines – when and at what hours each episode was played.
Heatmaps of viewing time – calendar-style visuals that reveal your busiest Netflix months.
In short, the project turns your Netflix data into a personalized dashboard of your streaming story.
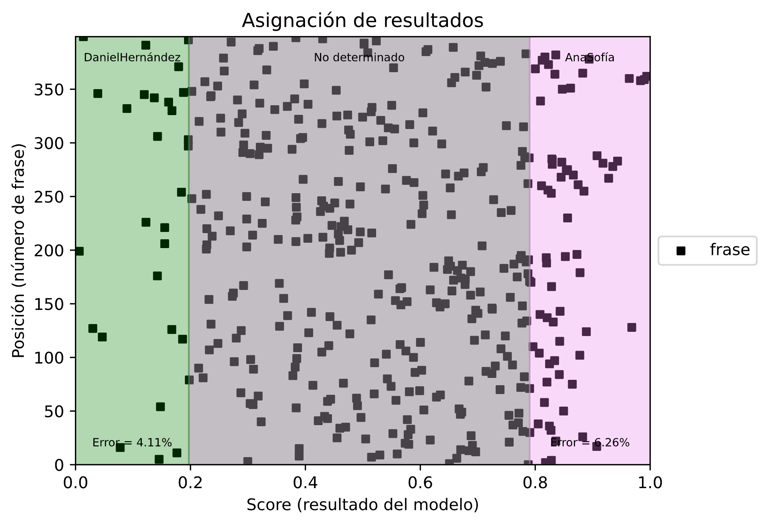
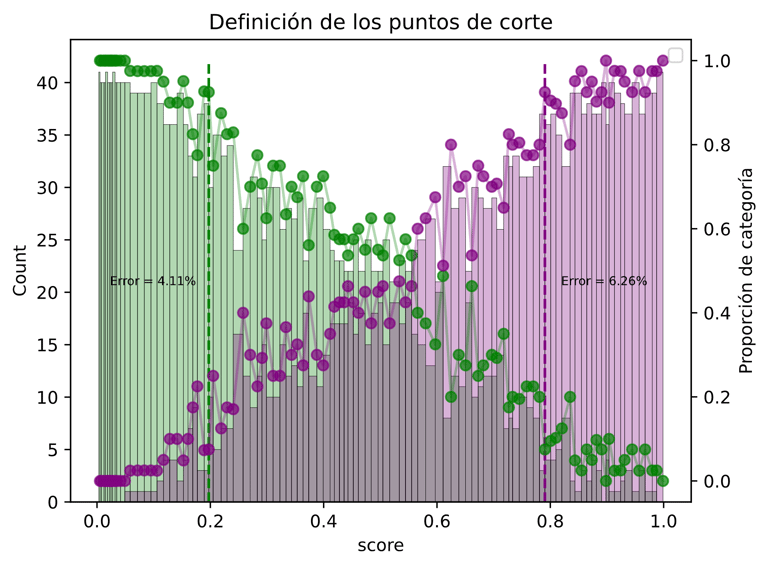
Whatsapp Data
A project that turns your Whatsapp data into a model that identifies who is the most probable to say certain phrases.
The model
This project develops an AI called Personality, designed to learn from individual phrases in a conversation. Its main goal is to predict whether a specific phrase is more likely to have been said by one user or the other, based on conversational patterns.
The project highlights how AI can capture unique communication styles and apply them to practical problems like authorship recognition or conversational analysis. By learning from real WhatsApp chat data, the system becomes more personal and relatable, showing how machine learning can bridge the gap between text and identity.
With a simple setup, the project automatically installs dependencies, processes the WhatsApp conversation, and trains a model that:
Learns phrase by phrase from your chats.
Predicts authorship of any given line.
Offers a foundation for exploring language patterns, personality traits, and conversational dynamics.
In short, it turns ordinary chat history into a smart AI experiment on language and identity.
PREMOV
An idea for a mathematical model that predicts forest fire movement in real time to support faster, safer, and more sustainable firefighting.
What is the project about?
The Premov project is an idea or proposal for a mathematical modeling tool designed to predict the movement of forest fires in real time. Its goal is to provide more accurate and faster insights into how fires spread, allowing for effective strategies that protect ecosystems, reduce risks, and improve resource management during emergencies.
Forest fires are a growing threat worldwide, and in Mexico alone, thousands of hectares are lost every year. Traditional firefighting methods often lack efficiency, putting both ecosystems and people at risk. Premov addresses this by combining geographic, meteorological, and vegetation data to model fire dynamics, offering decision-makers a science-based way to act quickly, safely, and sustainably.
Premov integrates data from drones, sensors, and meteorological stations to map terrain, vegetation, and environmental conditions. With this information, the model simulates fire behavior using a probabilistic approach, improving accuracy compared to deterministic models. Its applications range from training scenarios and risk mapping to real-time fire control, helping authorities build firebreaks, allocate resources more efficiently, and reduce human risk.
In short, Premov transforms cutting-edge science into a powerful ally for forest fire prevention and sustainable ecosystem management.